Don't trust, verify
What crypto already taught us that AI is about to learn the hard way
Over the past few months, I've been exploring the ins and outs of AI. I'm learning how it's trained, how it works, and how we attempt to understand it. And in every step of the way I keep thinking to myself… we're going to make the same mistakes all over again.
Crypto(graphy/currency) exists because we've learned that we can not trust the people who run our world. And time and time again it proves its thesis correct - sometimes ironically by being the very thing it's supposed to be against. When we blindly believe what governments and companies say, we get burned.
Some examples you might remember: The 2008 Financial Crisis, Mt Gox, FTX, Wirecard. Even outside of finance: Volkswagen Dieselgate, Chernobyl, Cambridge Analytica, and well… basically everything Big Pharma has ever done.
All of these happened because of the most boring failure imaginable: we just believed they were honest. The lesson that crypto takes away from these collapses is something the cypherpunks had been saying since the beginning: don't trust, verify.

I think AI is about to learn this the hard way. An AI lab tells you that its model is safe, that when you're using enterprise subscriptions it doesn't train on your data, that the model answering your prompt is the same one they published reports on. Every one of these is a self-reported claim about a system you can't inspect. And the only people who can inspect it are the people who have incentive to make the claim.
Over the last decade crypto has been learning and re-learning that self-reported claims about systems you can't see into are worth nothing. So we built the cryptography to give us claims that mean something.
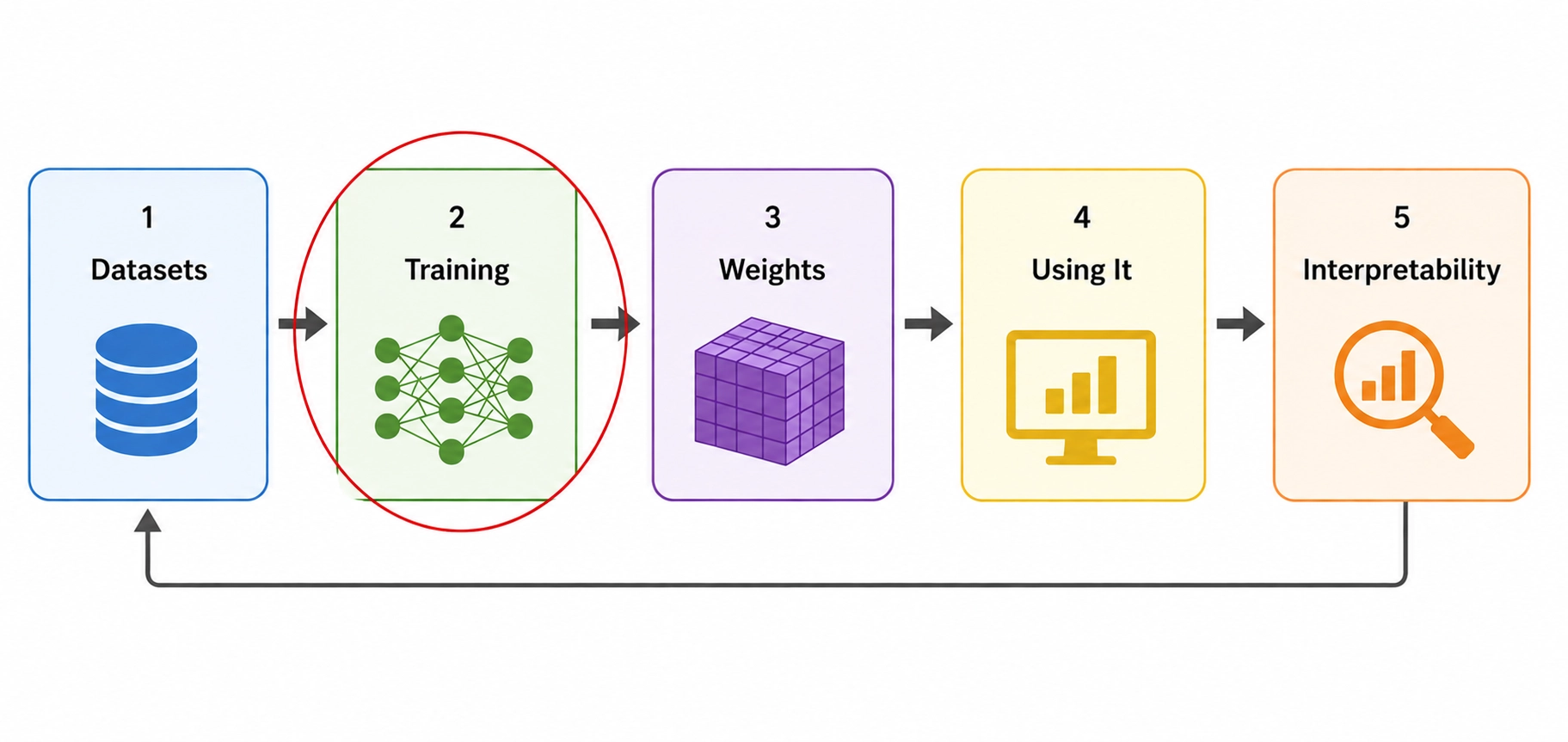
In this article I'm going to walk through the lifecycle of an AI model - from the data it's born from to the answers it gives. I'll explain at each stage why we need to apply the principles of "don't trust, verify". And propose how we can do so practically.
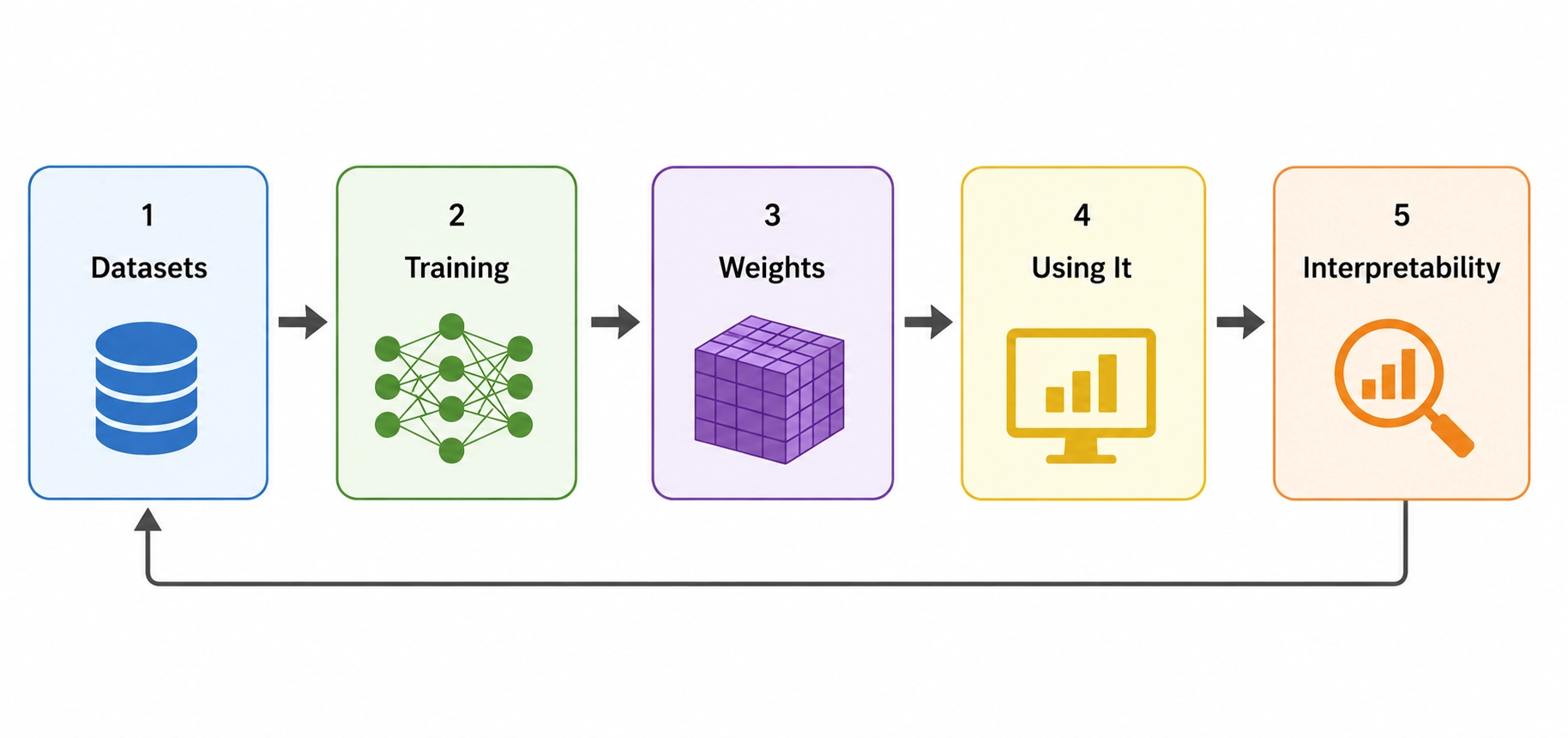
AI identity - datasets and weights
Proving a model is what it says it is
An AI model is given a bunch of data and ends up as a series of weights. Neither their data nor their weights are public - good. Which means they are not verifiable - bad.
When a lab says that the model serving your API request is the model it says it is (and not some sort of cheaper version of it a few weeks after its initial release), you have no way to check. There is no binding between the artefact and the claim about it.
Crypto solved the binding problem with commitments. You publish a cryptographic, irreversible hash of a thing, and from then on you can prove the thing matches the hash without revealing the thing itself, and you cannot change the thing without everyone noticing. This ports over to AI datasets and weights pretty easily.
The dataset gets a commitment, ie a public hash of exactly what went in. That way, if the dataset changes, the hash will change too.
For finding out more information about the data the model is trained on, we can go further with Merkle trees. In crypto, exchanges use proof-of-reserves systems to prove that a particular account is included in a larger balance sheet without revealing everyone else's balances. We can do something similar for training datasets - a user or company verifies that a dataset they contributed was included in training without revealing the rest of the dataset.
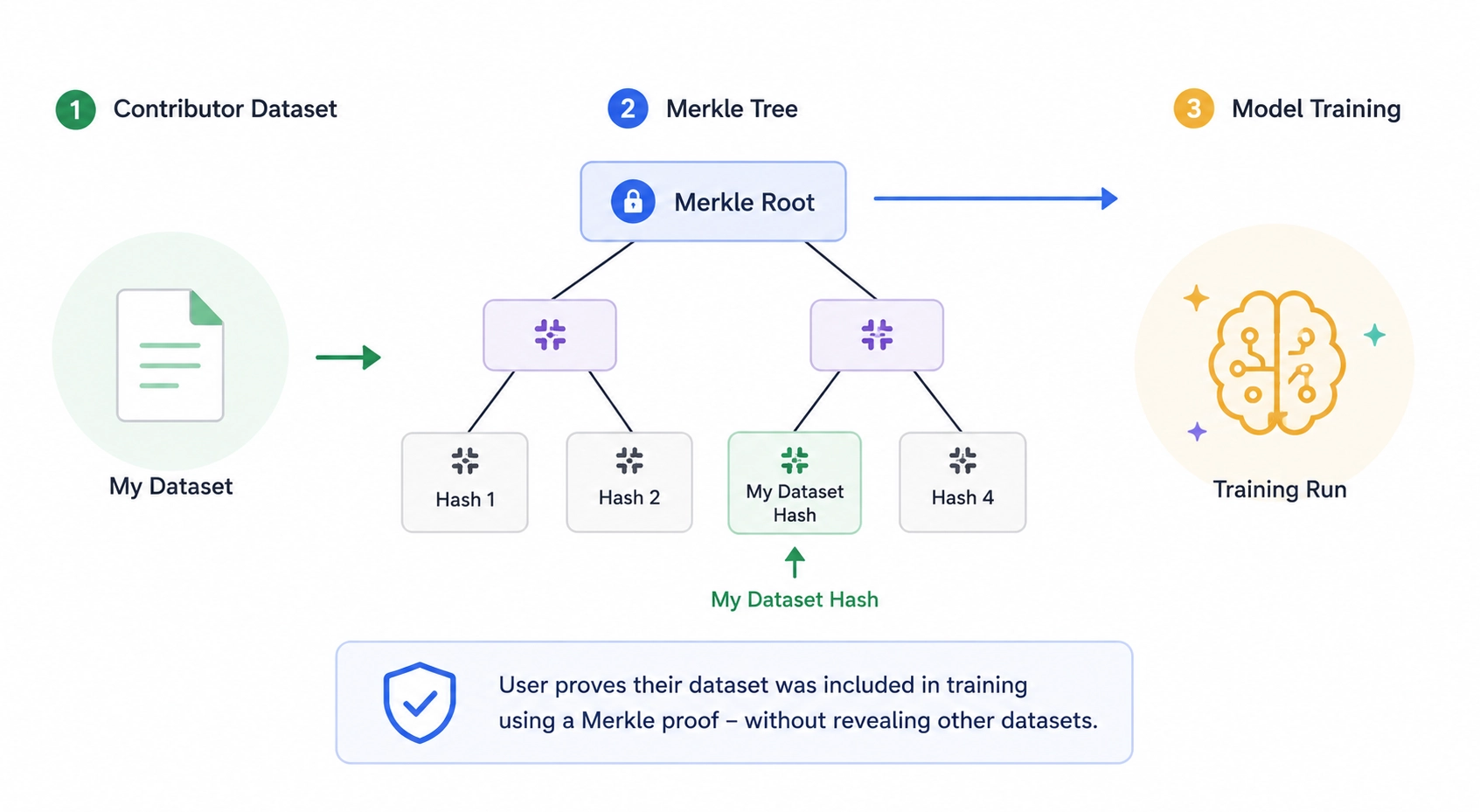
Proving exclusion of data is harder. It's easy to prove that something is in a committed dataset, but proving that something isn't (like your private messages) remains an open problem. Maybe the desire to build verifiable AI will help us solve this.
When training finishes, the weights can get a commitment too, giving us a hash of the actual finished model. We now have a cryptographic string that binds to this specific model. Both commitments are public and checkable by anyone.
But a published commitment, on its own, doesn't actually prove anything about the model you're talking to. It proves a model with that hash exists somewhere - it does not prove that the thing answering your prompt right now is that model. Anthropic could publish a commitment to Opus 4.8 and then quietly serve you Sonnet, and the commitment would just sit there meaning nothing.
The commitment is only worth something once it's bound to the live deployment, proving the model you are using is the one that is committed.
There are lots of ways to do this binding. The best is probably a zero knowledge proof of inference: the lab proves the output was produced by the committed model without revealing all the information about the model. Projects like EZKL and Lagrange's DeepProve do this - you compile a model into a ZK circuit and then anyone can verify the proof. But right now it's way too expensive for LLMs and complex neural networks.
Another option is to run the model inside a TEE and have it sign an attestation saying "this exact model ran." Phala is the best example of this.
I built an example of the TEE route (it does some extra things too that we'll get to later). It runs GPT-2 inside a TEE and cryptographically signs that the response came from GPT-2 inside this specific enclave, so every answer is tied back to the committed model.
Now you can actually check that OpenAI didn't quietly retrain your GPT4.0 boyfriend.
So this first stage is: commit to the data, commit to the model, and bind the live model to it so it's provably identical to the committed one. Without this, the rest of this article doesn't matter because you'd just be proving some property about a model that isn't the one answering your questions.
Training
Proving the model was made the way they say it was
A commitment proves what model you have. It says nothing about how it was made. Did the safety training get applied? Was the model actually trained on the data that was committed? Did the process described in the paper really produce this checkpoint?
There are multiple ways to allow verification for how a model was trained. The "best" way is to provide a zero-knowledge proof that proves training algorithms were run correctly without revealing the data they were run on.
Privately proving a training run is hard because you're proving literally millions of floating-point operations, but it's a thing. Research on zero-knowledge proofs of deep learning training can now produce a proof of a single training step, for a sixteen-layer network with hundreds of millions of parameters, in under a minute and under 20kb. This produces a proof that the step happened correctly (ie "according to what they say") without revealing the training data or weights.
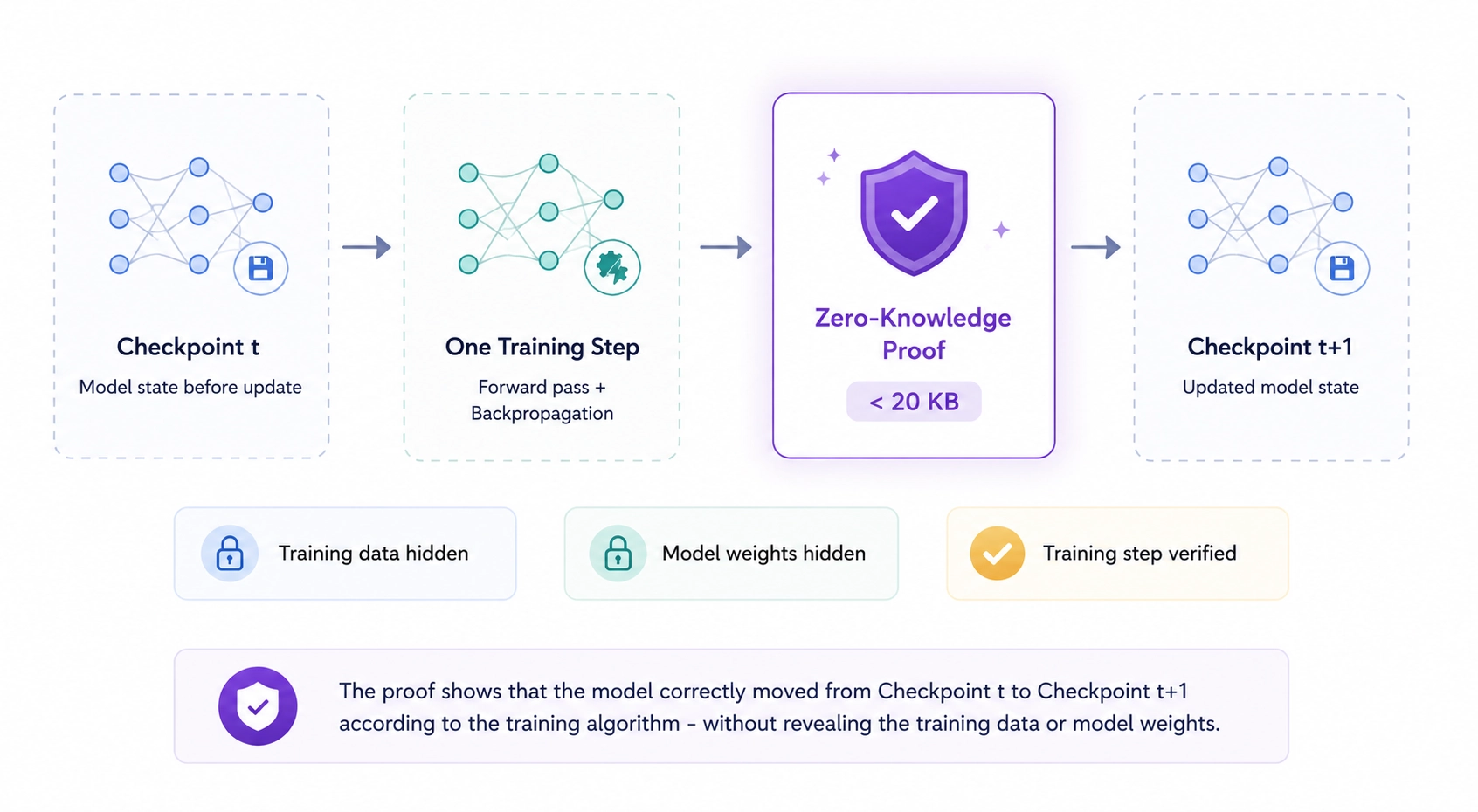
So now, instead of just committing to a specific blind checkpoint, we can bind a checkpoint to a specific committed dataset and verifiable training configuration.
ZK is the heaviest option, but it's not the only one. The lightest is something called proof of learning: the lab logs its checkpoints and gradients along the way so a verifier can re-run slices of the training and then check that they reproduce the same result. It's much cheaper and easier than ZK but it can be bit shady.
Collaborative training
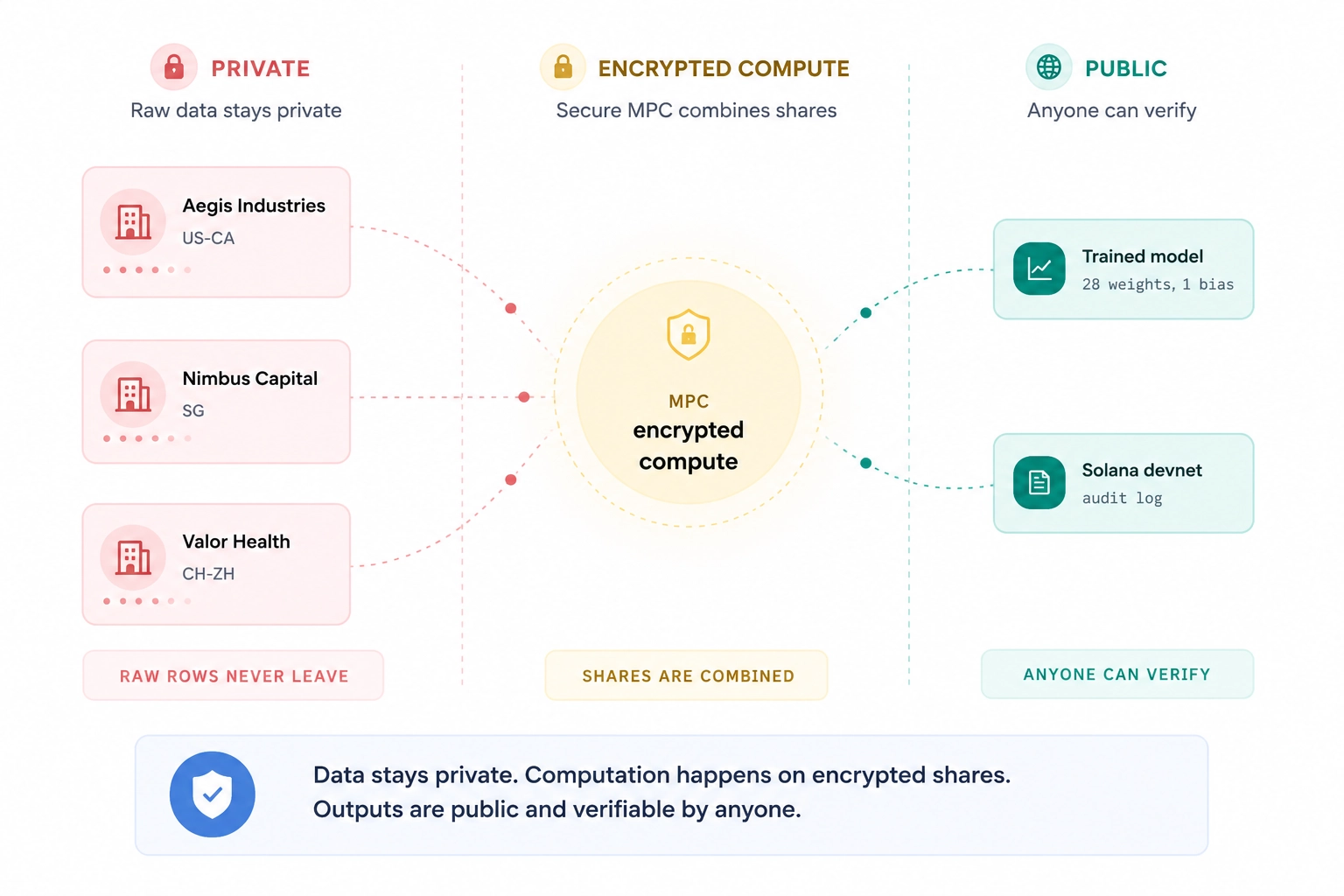
There are also cooler things we can do in this training step with cryptography we've built out already. For example, what if multiple parties want to train the same model on their data without sharing their data - even with each other? Hospitals can't share sensitive patient data with other hospitals without a ton of consent and paperwork. Wouldn't it be cool if they could bring all their data together to train a model on up-to-date medical information in specific regions?
I explored a way to do this with multi-party computation. Several parties can jointly train a model so that no individual party ever sees the raw inputs. Then using what we talked about before they can verify that their data was included in the model training and the training underwent the processes agreed upon. Realistically MPC is not powerful enough yet for the sort of models we're used to today but it's a cool proof of concept.
Decentralized training
Of course, also in line with the crypto ethos is the idea of decentralized training. Lots of people with GPUs come together to train a model with no single company owning all of the compute. Prime Intellect trained INTELLECT-2 (32B params, 100+ nodes) and Nous Research is coordinating the training of Psyche over Solana. In these scenarios, the control of objective, weights, and training protocol are still centralized. I am unsure if any major projects are working on decentralizing the entire stack of training a model - so let me know!
The audit problem
Allowing the public to understand models more deeply
This is the stage I've been enjoying the most. Interpretability is the exploration of why a model behaves the way it does. It is the closest thing we have to actually looking inside a model and seeing what it's doing, especially mechanistic interpretability. Interpretability researchers try to find which features correspond to which weights, how a model reasons, and try to predict how changing training could impact its behaviour.
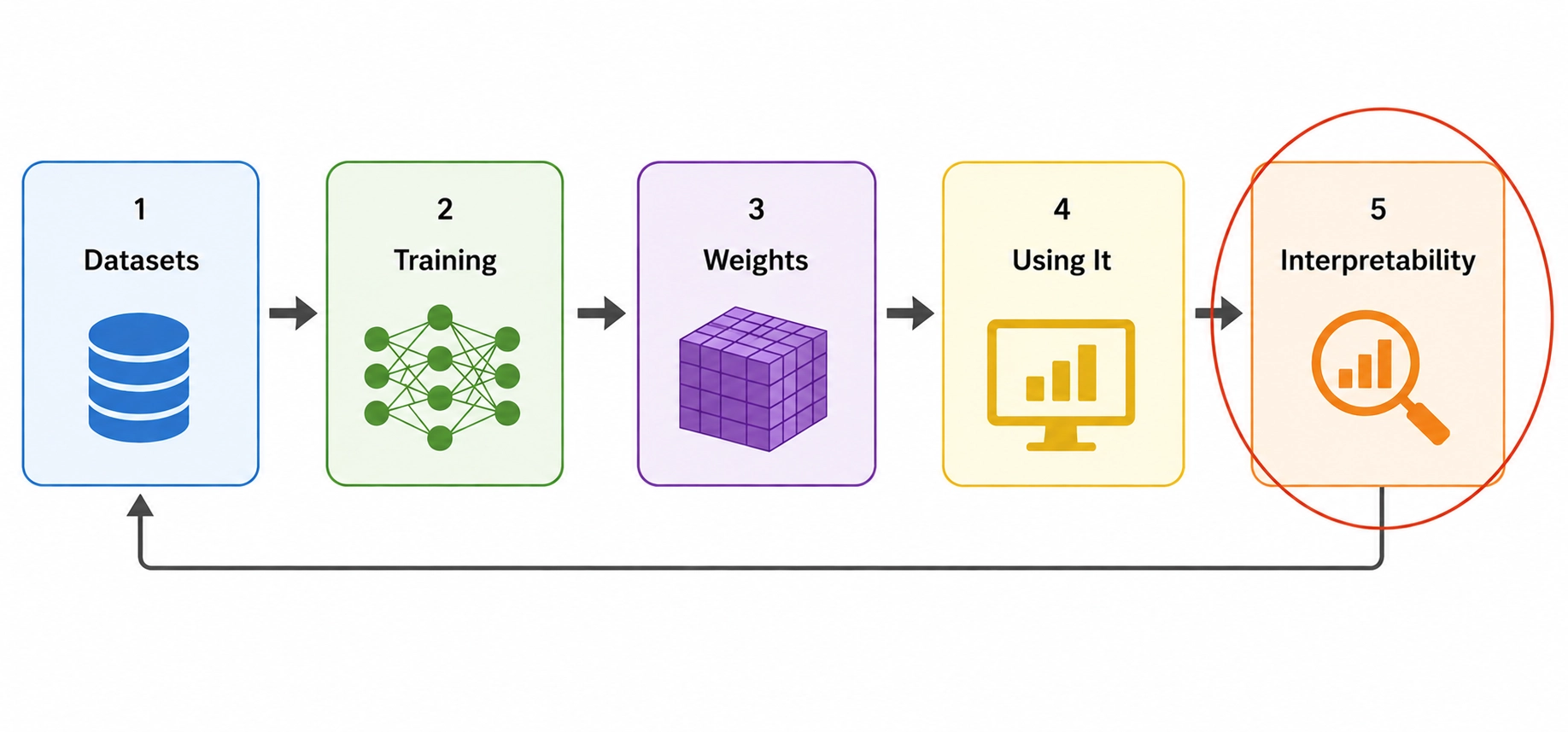
Interpreting a model can be considered similar to auditing a model. But right now it's done only by the employees at the labs who are building (and marketing) their models.
Imagine if the only people allowed to audit a bank's books were that bank's own employees, and the results were published as a friendly easy-to-read summary with the ledgers withheld. That's where we're at right now for model interpretability, and we've somehow decided it's normal. Even though 10x more people use ChatGPT than the most used bank in the world! (ChatGPT has ~800 million users, JPMorgan has ~80 million).
When a lab says "our interpretability work shows the model is safe" you are being asked to trust both the finding itself and the integrity of a process you can't see, run by people with for-profit incentives. It's a structural problem, not a problem of the researchers themselves (those people are cool).

OpenAI stopped building open AI for a fair reason - it isn't realistic to expect AI labs to publish all the weights and inner workings of the models that they use to compete and make profit.
Crypto has taught us that not everything needs to be open source, but we can publish enough for the public to help us with auditing. We can verify smart contracts on block explorers but keep backend logic closed source. Or projects like ZCash publish their circuits on GitHub but keep individual balances and transactions private. We've learned that we don't have to choose between "make everything public" and "hide everything".
Labs generally want to keep both the datasets and the weights of their models private. So we need a way to hide these from the public, while still publishing enough information for interpretability researchers to do their thing.
It turns out that keeping the data private doesn't necessarily destroy the explanation or interpretability of a model. I replicated a research paper on explainable models over private datasets. In the paper, they anonymized and mixed up the underlying dataset and then checked whether the model's feature attributions still hold up. They found that it is actually possible to privacy-protect the inputs and still get explanations that are faithful enough to be useful. Not entirely the same, but close. So privacy of data and interpretability of the model are not in conflict.
Keeping the weights private doesn't have to destroy the audit either. The GPT-2-in-a-TEE exploration I talked about earlier also explores this. On each request it publishes per-layer top-token predictions, attention focus aggregates, activation-patching recovery scores, and some other things useful for doing interpretability experiments, while refusing to return raw activations, gradients, or projection matrices. I don't think we could call this "mechanistic interpretability" but we can get fairly close - it's much better than nothing, and it doesn't sacrifice any of the privacy of the AI lab.
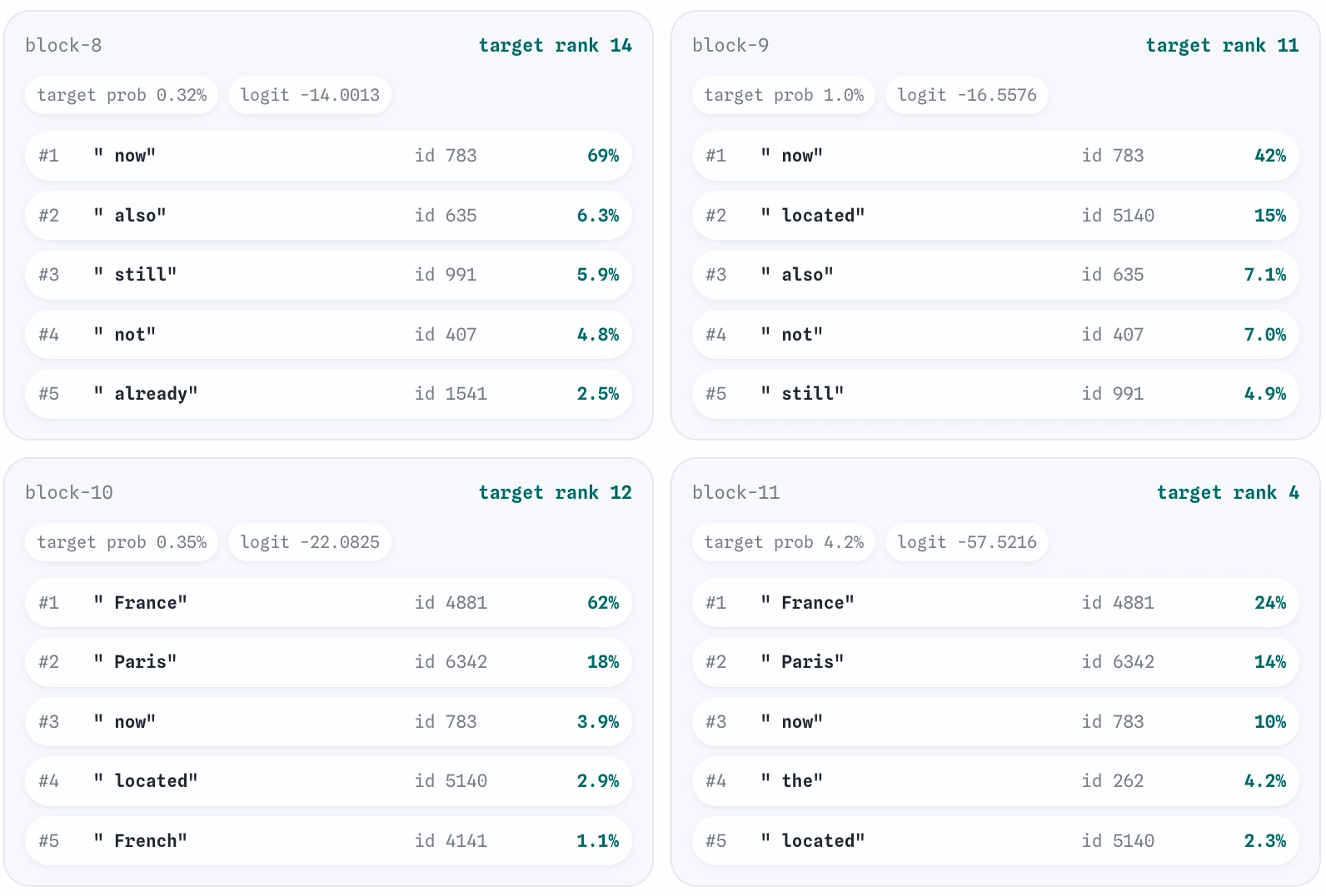
This image is what GPT-2 appears to be leaning toward at different transformer blocks for the text "The capital of France is". (GPT-2 wasn't the best.)
This stage is the one that turns AI into a public good.
Incentives and governance
Making sure we actually fix the problems
From the beginning, crypto has deeply understood incentives, like using staking as a mechanism to put your money where your mouth is. Paying people to be honest generally works better than expecting them to be honest on their own accord.
This has evolved into a culture of crowdsourcing audits and massive bug bounties. It's not just crypto - almost every important piece of software gives out bounties to users when they find bugs, encouraging them to report issues so they can be fixed.
If we have a verification chain laid out this article, it would be possible for people to find bugs or mistakes in model deployment. This allows for public bug bounties on AI models, meaning the world is incentivized to together to keep AI developers honest and consistent.
After a bug or inconsistency is reported, we need a system for deciding whether or not this is really a bug and, if so, does the model need upgraded.
Early crypto believed that "code is law" - if you write the rules into a smart contract you'll never need human judgment again. This meant that bug exploits were just and legal, because what defines a bug? More importantly, in a decentralized system, who defines a bug? The code of course! It's an interesting philosophical conversation but we eventually realized that "code is law" is quite ridiculous, and we can all somewhat align on what defines a bug, so we intervened as humans to hard fork or roll back.
I can see us heading this direction with AI, delegating it with a lot of control without delegating responsibility (Milei is even encoding this limited liability into law). We're not far away from thinking that a sufficiently good model spec or constitution removes the need for ongoing human governance. It doesn't. We need a transparent, governed, upgrade path, and we should design it before we need it. What that looks like - well, I don't know. This article is about cryptography.
Putting it all together
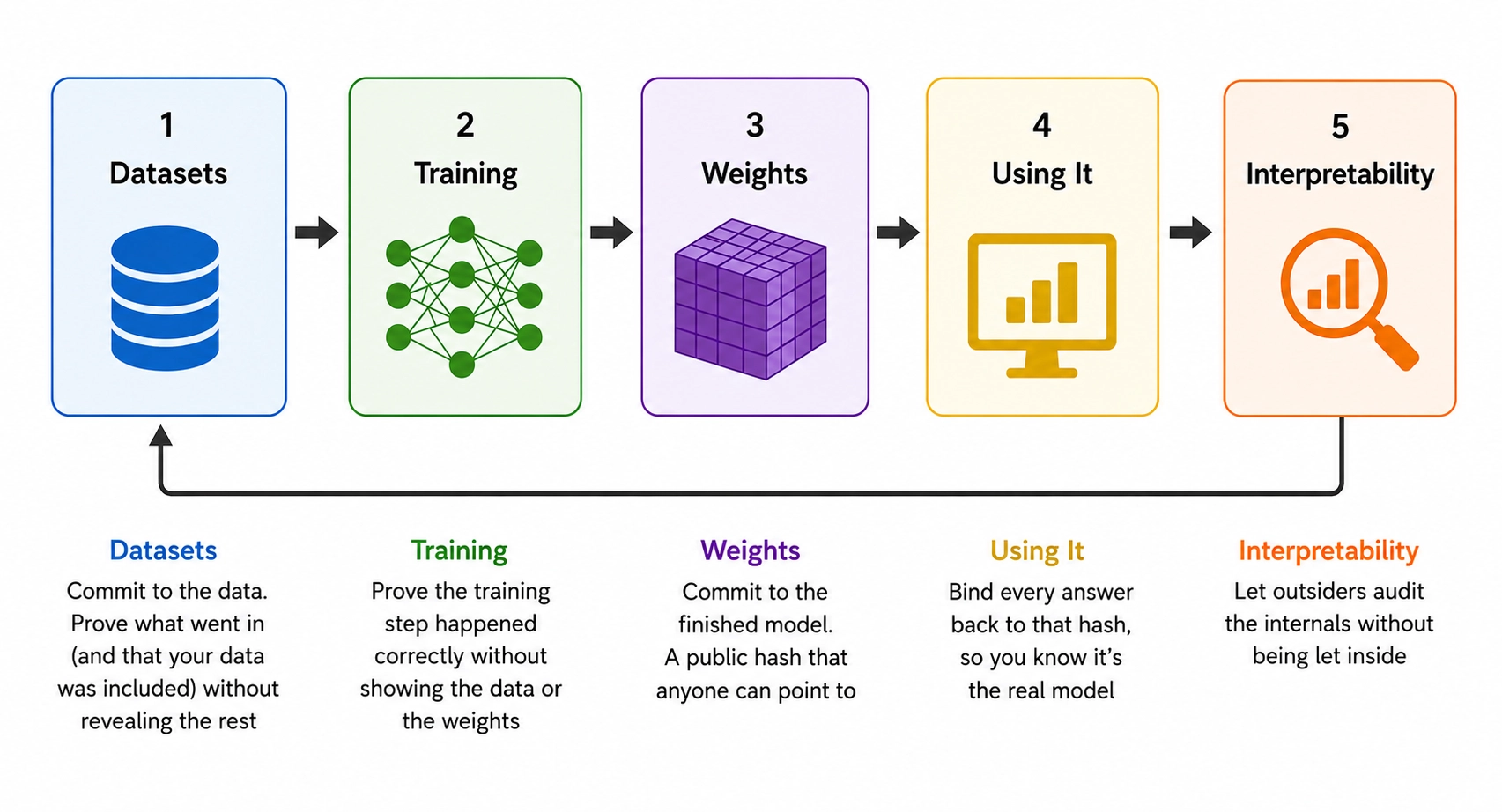
Walk back up these stages and notice what we proposed: a commitment to the data and the model, a proof of how it was trained, a receipt for every answer it gives, and an incentivized way for outsiders to audit its internals. Every piece is tamper-evident and checkable by anyone. This structure already has a name: it's a blockchain.

AI is about to become the most powerful infrastructure we've ever built, and we are currently giving AI companies a level of trust that we've already learned never to give to anyone. Maybe we shouldn't wait for the AI equivalent of FTX to figure out that "trust me bro" wasn't a good idea. The tools to do better already exist. We built them the last time! So let's learn from our mistakes and build the next weird world of technology together.
In short - Don't trust. Verify. It was true for money. It's more true for intelligence.